利用python从网站:https://pic.netbian.com/
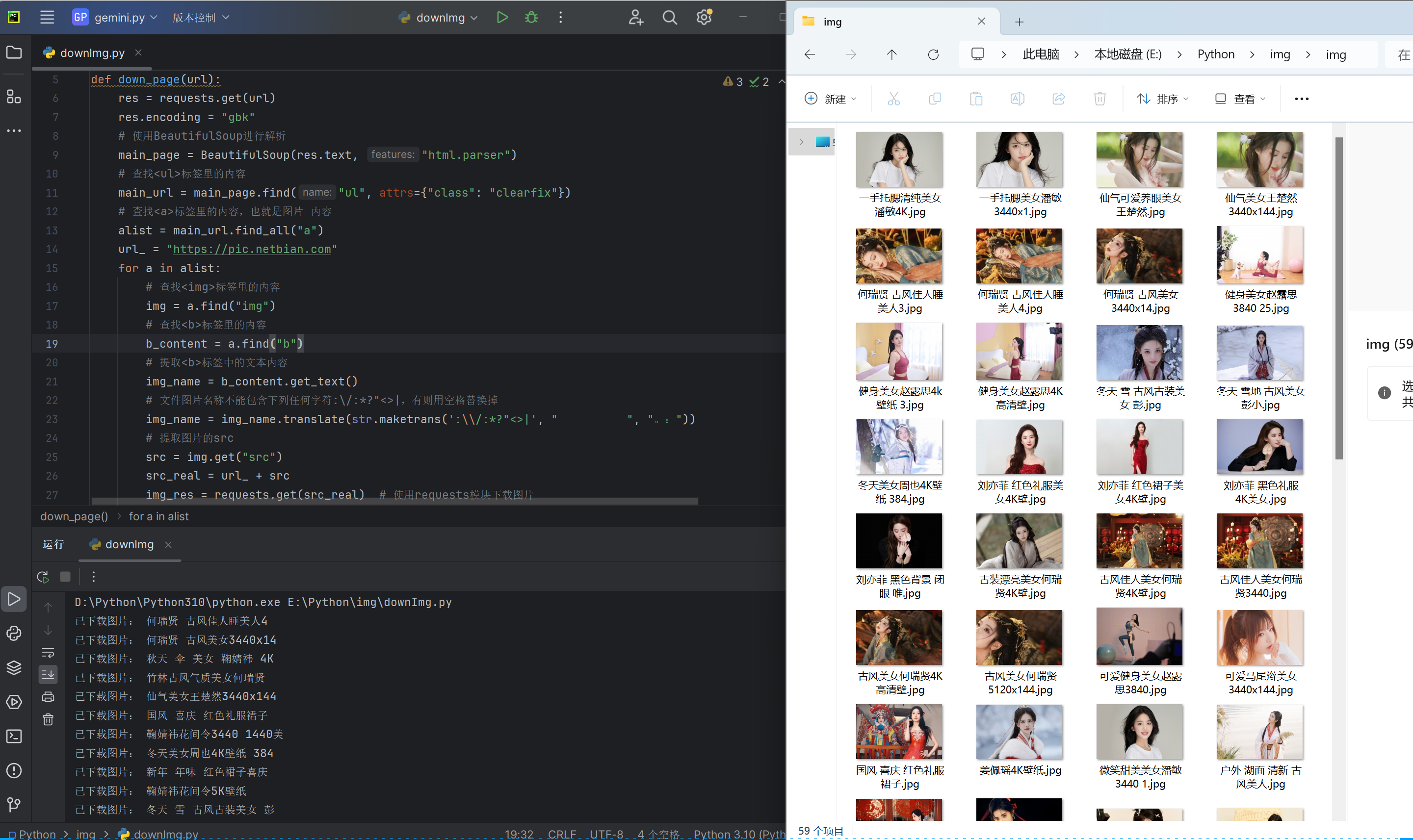
批量下载图片并保存到本地。效果如下:
完整代码:
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor
def down_page(url):
res = requests.get(url)
res.encoding = "gbk"
# 使用BeautifulSoup进行解析
main_page = BeautifulSoup(res.text, "html.parser")
# 查找<ul>标签里的内容
main_url = main_page.find("ul", attrs={"class": "clearfix"})
# 查找<a>标签里的内容,也就是图片内容
alist = main_url.find_all("a")
url_ = "https://pic.netbian.com"
for a in alist:
# 查找<img>标签里的内容
img = a.find("img")
# 查找<b>标签里的内容
b_content = a.find("b")
# 提取<b>标签中的文本内容
img_name = b_content.get_text()
# 文件图片名称不能包含下列任何字符:\/:*?"<>|,有则替换掉
img_name = img_name.translate(str.maketrans(':\\/:*?"<>|', " ", "。:"))
# 提取图片的src
src = img.get("src")
src_real = url_ + src
img_res = requests.get(src_real) # 使用requests模块下载图片
with open("img/" + f'{img_name}.jpg', mode="wb") as f:
f.write(img_res.content)
print("已下载图片:", img_name)
if __name__ == '__main__':
# 使用多线程 ThreadPoolExecutor
with ThreadPoolExecutor(10) as t:
for i in range(4, 5):
# 假如i为4、5:
# 则下载https://pic.netbian.com/4kmeinv/index_4.html 和 https://pic.netbian.com/4kmeinv/index_5.html 两页的所有图片
print(i)
t.submit(down_page, f"https://pic.netbian.com/4kmeinv/index_{i}.html")
# 所有任务提交完成后,关闭线程池
t.shutdown()
print("全部下载完毕!!!")
PS:请自行安装所使用的库、创建img目录
pip install requests pip install bs4 pip install concurrent
代码步骤:
- 导入所需库:
- 在代码的开头导入了需要使用的库,包括
requests用于发送HTTP请求,BeautifulSoup用于解析HTML,以及ThreadPoolExecutor用于实现多线程。
- 在代码的开头导入了需要使用的库,包括
- 定义下载页面函数:
- 创建了一个名为
down_page的函数,用于下载页面内容和图片。 - 使用
requests发送GET请求获取页面内容,并指定编码为GBK。 - 使用
BeautifulSoup进行解析,解析网页内容,查找页面中的图片链接。 - 遍历所有图片链接,提取图片信息并下载到本地。
- 创建了一个名为
- 使用多线程下载:
- 在主程序中使用
ThreadPoolExecutor来实现多线程下载。 - 通过循环构造要下载的页面的URL,并将下载任务提交给线程池处理。
- 使用
submit方法提交任务,并指定要执行的函数和参数。 - 所有任务提交完成后,关闭线程池。
- 在主程序中使用
使用的方法:
- requests.get(url):
- 发送HTTP GET请求获取页面内容。
- 参数
url为要请求的页面的URL。
- BeautifulSoup(res.text, “html.parser”):
- 使用BeautifulSoup解析HTML页面内容。
- 参数
res.text为页面内容,”html.parser”表示使用HTML解析器。
- find(name, attrs) / find_all(name, attrs):
- 在HTML文档中查找指定名称和属性的标签。
find用于查找单个标签,find_all用于查找所有符合条件的标签。
- translate(table, deletechars):
- 替换字符串中的字符。
table参数指定要替换的字符映射表,deletechars参数指定要删除的字符。
- requests.get(url).content:
- 获取HTTP响应的内容,以字节形式返回。
- 可以用于获取网页的二进制数据,例如图片文件。
- **ThreadPoolExecutor(max_workers).submit(func, *args, kwargs):
- 使用线程池执行函数。
max_workers指定线程池中的最大线程数,submit方法用于提交任务给线程池执行,其中func是要执行的函数,*args和**kwargs是函数的参数。



